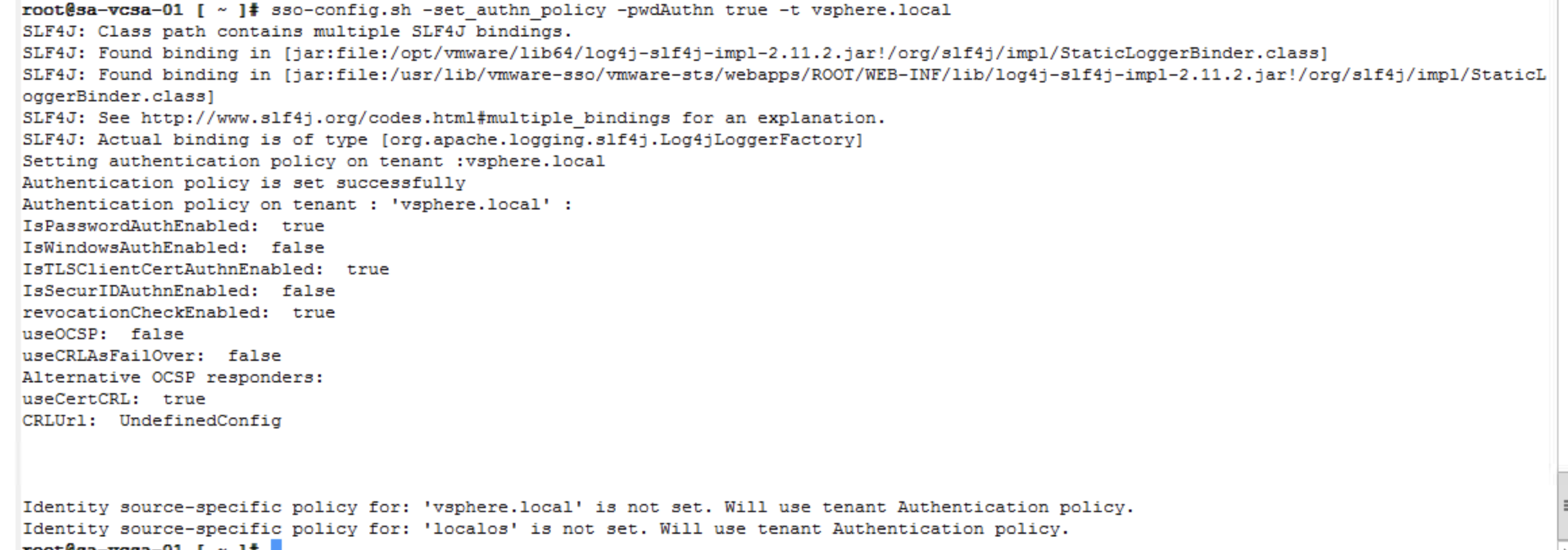
These days due to Pandemic, whole world is struggling to support remote workforce. In this case there is Cloud based VDI solution available from VMware which is VMware Horizon Cloud on Azure, in this you can Bring your own Azure Infrastructure and use it for running the workloads for remote workers with the help of Horizon Cloud on Azure. You need Few Subscriptions needed for this setup:
1. Azure Subscription (BYO Subscription)
2. Horizon Cloud on Azure Subscription (Get it from VMware)
3. Windows Licenses (Check Microsoft Website)
In this post, i will discuss about if you have created RDSH Farm in Horizon Cloud on Azure then what are the power management modes available and how these are helping organizations to minimize the cost of running Desktops in the Cloud.
Workflow of Publishing Apps and Desktops in VMware Horizon Cloud on Azure
RDSH Farm is basically the collection of RDS Servers with similar configuration
Power Management Modes
There are three power management modes available in Horizon Cloud on Azure
Low Threshold = This is used to Power off the RDS Server in RDS Farm
High Threshold = This is used to Power on the RDS Server in RDS Farm
Example Scenario
RDS Farm Setting
- Min VMs = 1
- Max VMs = 2
- Session per VM = 20
- Power Management Mode = Optimized Performance
Serveral Users to whom RDS Farm is Assigned
Now as soon as this farm is created it will create 2 RDS VM's upfront, out of these two VMs one will be powered on as Min VMs is one. If Min VMs is Zero, no RDS VM will be powered on
Formula to Calculate Load
Active Sessions on RDS Server / Max Sessions Per VM * 100
When New Server Is Powered On?
In this example i have RDS Server with 12 Sessions and RDS 2 is Powered Off
12/20*100 = i have 60% load on RDS1, which is beyond optimized performance high threshold. Now RDS 2 will be Powered on and all new sessions will start on RDS 2.
If Both the servers usage is above the high threshold, New session is placed in round robin manner. Server which has less number of active connections will be selected, like in this example RDS2 will be selected.
When Existing Server Is Powered Off?
Now both the Servers usage is below high threshold as number of active sessions are reduced, lease loaded server will be quiesced and no new session will be placed on that server like in this example lease loaded server is RDS 2.
As soon as all the users will logout from RDS 2, RDS 2 will be powered off
This example is based on Optimized Performance mode. You can set any mode out of three modes, the only difference is different thresholds. Now you can notice the benefit of Power Management Modes is servers will be Powered off and Powered on automatically to help you in minimize the cost of running Desktops in cloud.