Since VMware vSphere Syslog Collector is part of
the vCenter media all you have to do is mount the ISO, click the vSphere
Syslog Collector menu then hit Install.
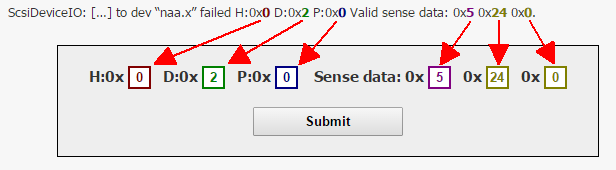
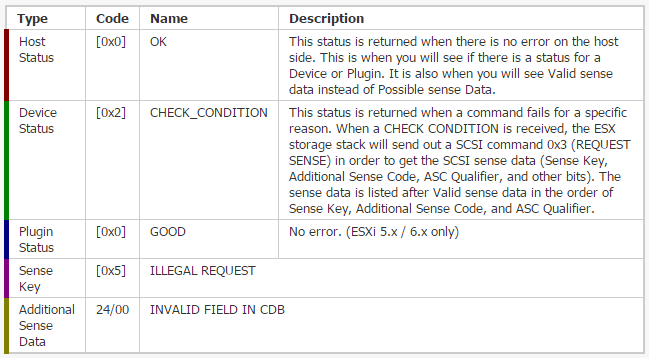
Question:- After setting up remote syslog collector, I see only one type of log file as syslog.log for all ESXi hosts.What all logs does it hold as generally if are checking the logs locally on an ESXi we look for hostd.log, vmkernel.log, vmkwarning.log & so on ?
So where are all these logs in syslog.log which is coming remotely ?
Question:- After setting up remote syslog collector, I see only one type of log file as syslog.log for all ESXi hosts.What all logs does it hold as generally if are checking the logs locally on an ESXi we look for hostd.log, vmkernel.log, vmkwarning.log & so on ?
So where are all these logs in syslog.log which is coming remotely ?
Answer:- It is combining your logs into the syslog.log file you are looking at for each host. I can confirm from a quick look at mine-
vobd
vpxa
vmkernal
hostd
fdm
vmkwarning
rhttpproxy
snmpd
hostd-probe

Select Language

Now click on next

Now select i accept the terms and click on next

Select the log file size before rotation and number of logs to keep as per your requirement

Select standalone installation

Configure the port numbers or either keep the default port number

Provide the syslog collector identification information

Click on install to start the installation

Click on finish button

Run this command to check the current syslog configuration at esxi

You can get more granular details on the different logs by running:

To set the remote host to log to you can run:
It’s possible to set multiple remote logging servers and you can specify the protocol to be used by running, for example:
esxcli system syslog config set –loghost vc01.vmlab.loc,tcp://10.10.10.1:514,ssl://10.10.10.2:1514After making changes, it is recommended that you reload the syslog daemon:
If you have set up your hosts to log to a remote syslog collector but the logs aren’t showing up, then you should check your hosts firewall configuration to ensure that the syslog ports are open:

You could also set this using esxcli by running:
To test your syslog configuration you can ‘mark’ all logs with a custom message by running:
Then Move to the Syslog Server and Check this directory:-
c:\programdata\vmware\vmware syslog collector\data\your esxi host ip address folder\syslog.log and search for the test message